突破8小时边界:GLM-5.1如何重新定义AI模型的能力标尺
2025年4月8日,智谱GLM-5.1模型正式开源发布。这是继ChatGPT掀起的对话狂潮之后,又一个值得技术圈关注的里程碑节点。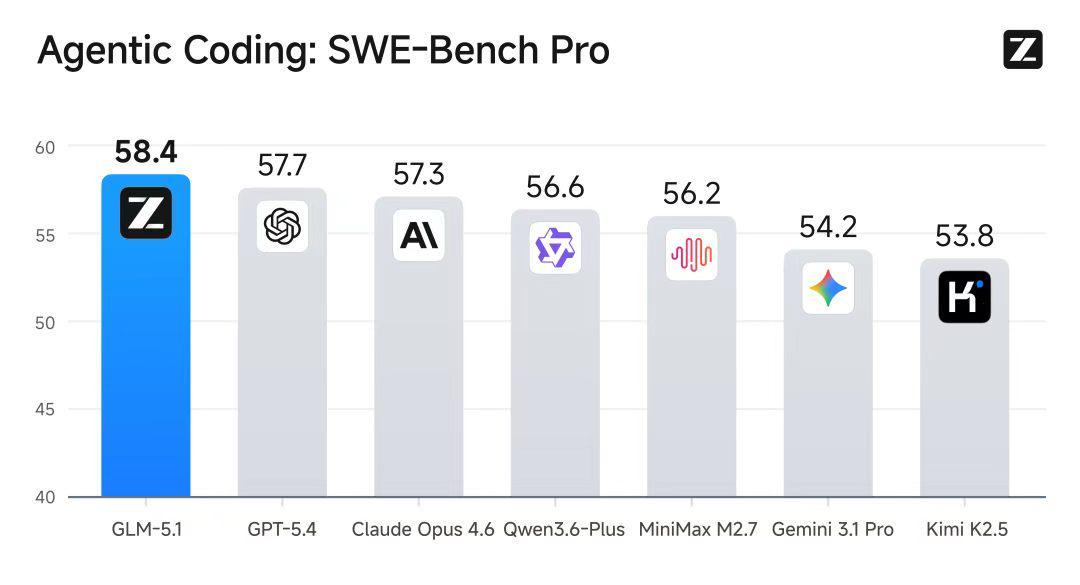
长程任务:AI从“对话玩具”走向“生产力工具”的关键一跃
长期以来,业界评估大模型能力的核心指标是Benchmark分数。SWE-BenchPro、Terminal-Bench2.0、NL2Repo——这些专业评测基准上,GLM-5.1均进入前列。但分数高低并不等同于实用价值。真正让GLM-5.1与众不同的是:它能在一次任务中独立、持续工作超过8小时,完成“规划→执行→交付”的完整闭环。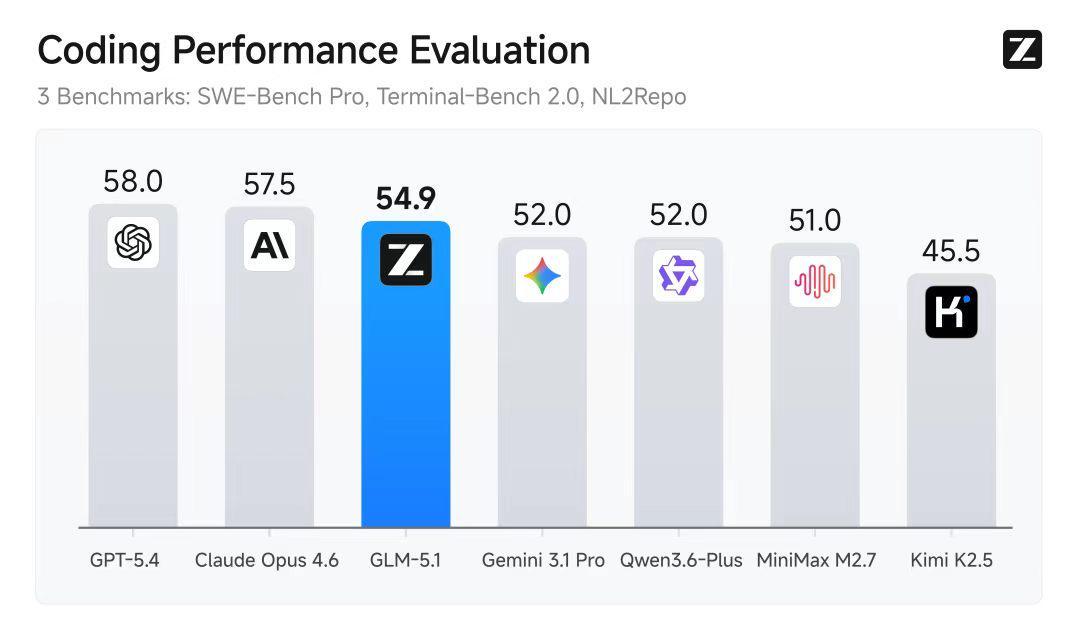
这不是简单的交互延长。传统模型以分钟级响应为单位,而GLM-5.1将时间尺度扩展到小时级,意味着它可以处理真正复杂的工程任务,而非停留在问答层面的玩具演示。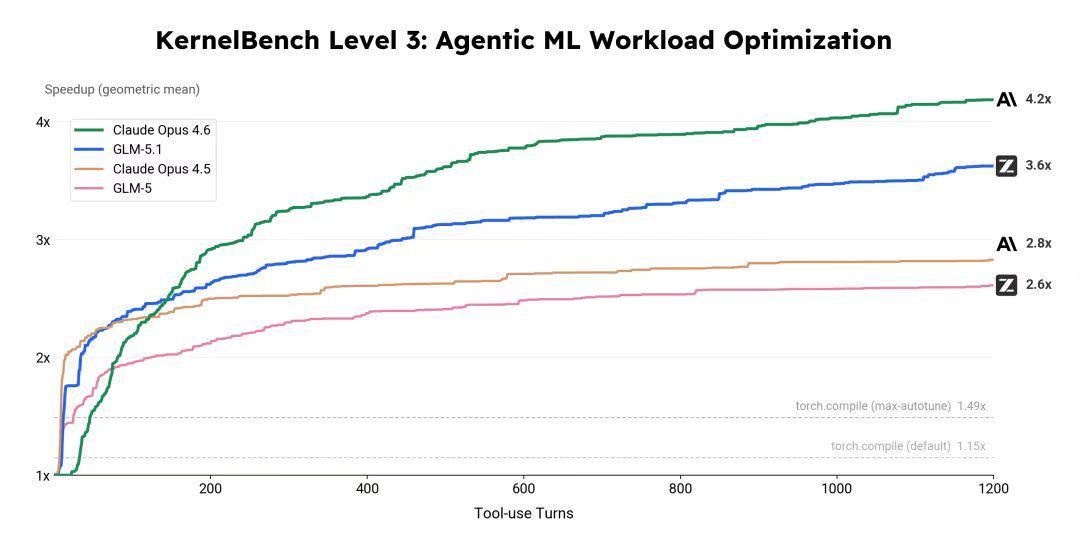
实战验证:8小时从零构建Linux桌面系统
技术参数之外,真实场景测试更具说服力。在8小时持续工作中,GLM-5.1完成了从零构建完整Linux桌面系统的任务:包含桌面环境、窗口管理器、状态栏、应用程序、VPN管理器、中文字体支持、游戏库等全套组件,执行超过1200步操作,生成4.8MB配套文件。
这个工程量此前需要4人团队一周时间。GLM-5.1用8小时完成了。
性能跃升:向量数据库优化与机器学习加速
桌面系统构建只是开始。在向量数据库优化场景中,GLM-5.1经过655次迭代,自主完成从全库扫描到提前剪枝的优化链条,查询吞吐量从3108QPS跃升至21472QPS——提升近7倍。
机器学习负载优化更具说服力:超过24小时迭代、1000轮工具调用,完成多轮编译、测试、分析、重写循环,最终实现3.6倍几何平均加速比。这不是实验室数据,而是真实生产环境的实测结果。
方法论提炼:长程任务执行的四大技术挑战
智谱团队指出,延长模型有效工作时长是提升智能体能力的基础维度。但这条路并非坦途,至少存在四大技术挑战:上下文焦虑问题(复杂任务下的上下文管理)、执行一致性问题(数千次工具调用后的状态维护)、局部最优跳出问题,以及最关键的——无确定数值指标任务上的自我评估机制建立。
谁先解决这四个问题,谁就掌握了下一代AI模型的入场券。